Conociendo la interfaz de Screaming Frog
Hola, soy Harold, y estoy ansioso por empezar con esta serie de guías y usos de Screaming Frog.
Si nunca has utilizado Screaming Frog cuando lo abres por primera vez puede ser intimidante ver la interfaz y tantas opciones, pero en este articulo te voy a enseñar cada opción y parte del software para que te des cuenta que no necesitas ser un científico para utilizarlo.
Instalando Screaming Frog
No tiene ninguna ciencia instalarlo, solo descárgalo desde este enlace, instala como cualquier software y ya. No voy a detenerme en esto.
Una vez instalado, inícialo por primera vez y veras esta pantalla a la que solo debes dar aceptar.
Conociendo la Interfaz
La interfaz de Screaming Frog cuando la ves por primera vez puede ser atemorizante (y sí que lo es) pero poco a poco vas utilizándolo vas comprendiendo mejor que hace cada parte. De mi parte trataré de explicar que es cada cosa.
Esta imagen te sugiero que la abras en grande en otro tab del navegador para que te sea mas fácil seguirlo.
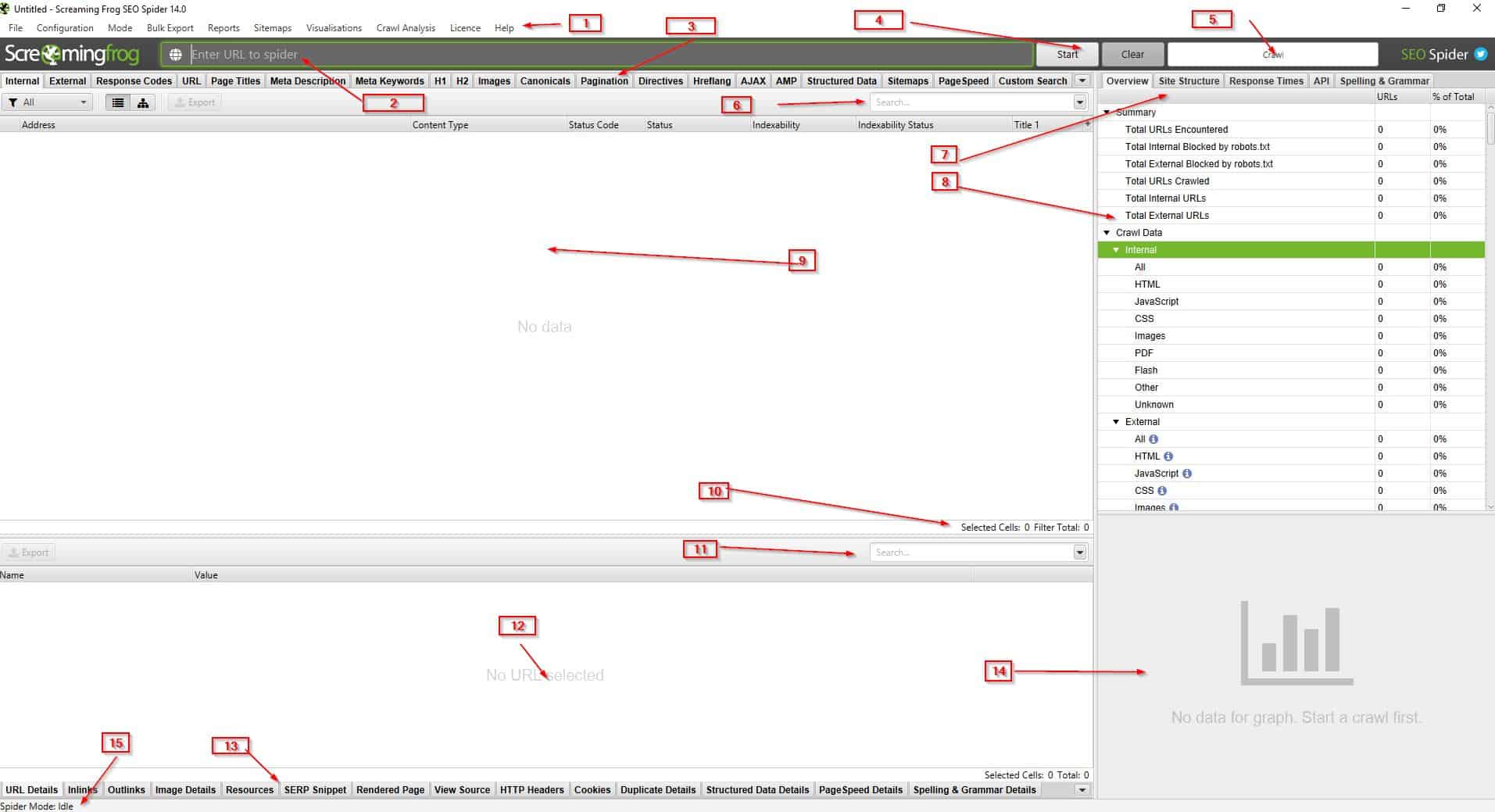
- Menú principal de navegación
- Barra para la URL: URL a rastrear
- Tabs principales
- Botones de acción
- Estado de crawleo
- Filtro principal
- Tabs laterales
- Información de los tabs laterales
- Información crawleada
- Selección y Total de URLs de contenido
- Filtro en tabs inferiores
- Información de tabs inferiores
- Tabs Inferiores
- Gráfico de crawleo de los tabs principales
- Modo seleccionado
1- Menú Principal
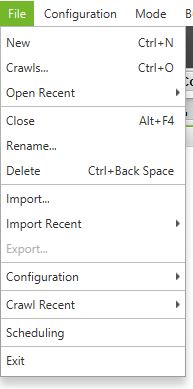
- File: Opciones para manejar los diferentes proyectos que vayas haciendo
- Configuration: Todas las opciones para configurar el comportamiento del robot (estas opciones están deshabilitadas en la versión free):
- Spider: Las opciones de que y como debe rastrear la araña
- Crawl: Las opciones de que debe rastrear y almacenar la araña
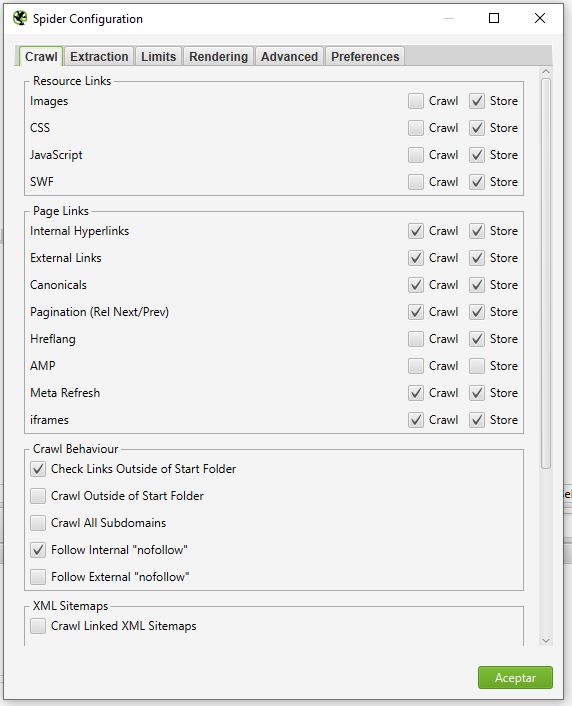
- Extraction: configuración de que debe extraer la araña de cada URL.
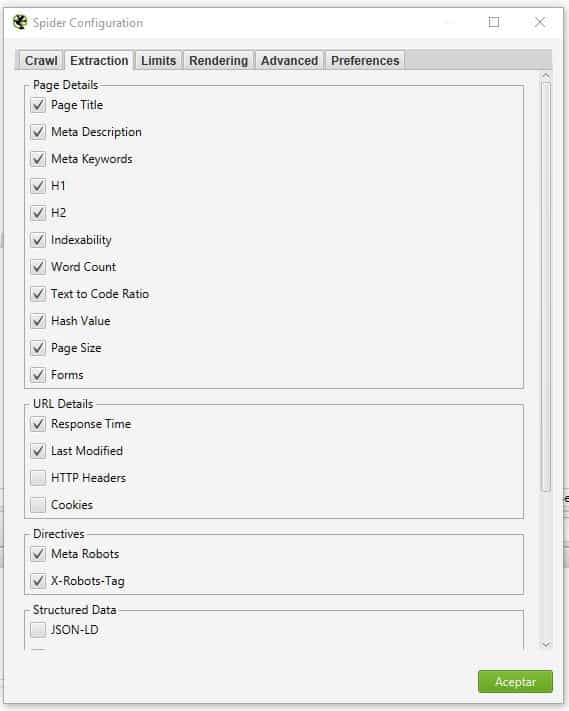
En esta lista de opciones no hay mucho donde perderse, pero quizá las importantes a configurar son: HTTP Headers, la información de datos estructurados, y almacenar el HTML, ojo, esto último va a ocupar mucho espacio en RAM y disco. - Limits: Configuración de los límites que va a tener la araña. En general para evitar que Screaming Frog nos tire el sitio o consuma toda la RAM del ordenador si se tiene un sitio demasiado grande. Existen configuraciones para el caso de sitios grandes que veremos más adelante.
- Limit Crawl total: el total de URLs que deseas extraer, en la version FREE está limitado a 500, en la de pago pone default 5 millones pero podes poner el valor que necesites.
- Limit Crawl Depth: la profundidad que deseas rastrear desde el punto de inicio que hayas elegido en la URL a rastrear. Se refiere a la profundidad de clicks. Si estas empezando en la home y colocas un valor de 2, no hará mas de dos clics desde la home en profundidad.
- Limit Max Folder Depth: Similar al punto anterior pero en este caso a nivel de profundidad de la URL.
- Limit Number of Query Strings: Si tienes URLs con parámetros, con esta opción puedes limitar hasta cuantas variables dentro de la URL quieres que la araña rastree o tome en cuenta.
- Max redirects to follow: Si tienes varias redirecciones internas (y no lo sabes o tienes mal una configuración) con esta opción puedes limitar cuantas redirecciones internas seguir antes de detenerse. Imagina que tienes 5 redirecciones y este valor esta en 3, al llegar a la 3ª redirección no continuara y así puede evitar entrar en un loop infinito a lo dr. Strange.
- Max URL Length to crawl: limitar el largo de las URLs a rastrear, el valor máximo es 2000.
- Max Links per URL to crawl: limita la cantidad de enlaces a rastrear en cada URL.
- Max Page Size (KB) to crawl: limita el tamaño de las páginas a rastrear, por ejemplo si tienes páginas que sabes son muy pesadas, puedes evitar rastrearlas con esta opción.
- Rendering: Permite elegir como va a “interpretar” el contenido extraído.
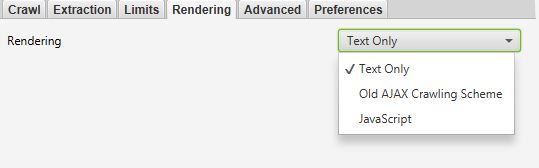
- Text only: Extrae el HTML puro únicamente. Ignora el rastreo por AJAX y el javascript del lado del cliente.
- Old Ajax Crawling Scheme: La araña va a obedecer el ahora obsoleto Ajax Crawling Scheme de Google si estuviera presente, de lo contrario va a funcionar como si fuera Text Only, es decir, extraer el HTML puro.
- JavaScript: la araña va a ejecutar el JavaScript del lado del cliente para interpretar la página, esta basado en chromium, por lo tanto funcionaria como si la página estuviese sido visualizada en el navegador Chrome.
- Advanced: Configuraciones un poco más avanzadas para el uso de la araña.
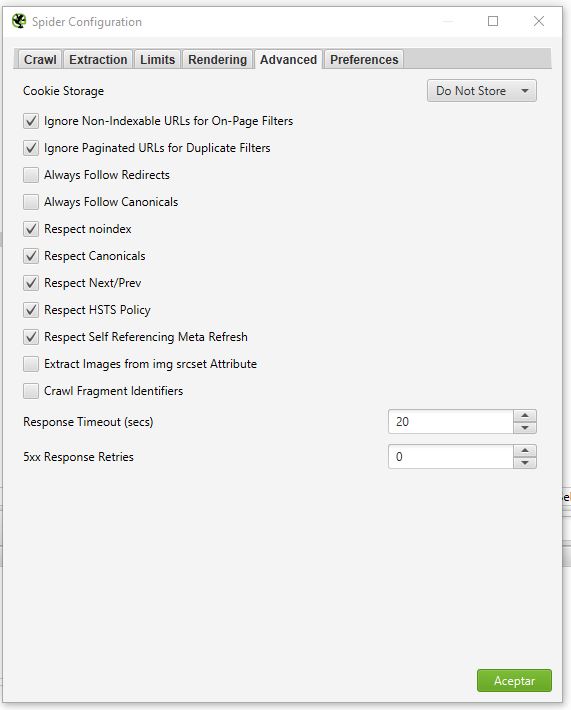
- Cookie Storage: Puedes configurar la araña para que utilice las cookies de la web lo que en algunos casos puede significar cargas de web más rápido, y también existen sitios que si no se aceptan las cookies no permite navegar. Default, la araña va a aceptar las cookies para “session only” que significa que la cookie va a existir solo durante la carga de la página pero va a dejar de existir cuando cambie de URL, pero puedes configurarla como persistente también para que la cookie siga existiendo entre URLs, donde la cookie se comparte en cada hilo de la araña pero no es almacenada, así que puedes estar tranquilo.
- Ignore non-indexable URLs for on-page filters: si se habilita esta opcion, la araña solo va a considerar las paginas indexables en el filtro como en el tab de Titulos, Meta descriptions, H1, y H2.
- Ignore paginated URLs for duplicate filters: al igual que la opcion anterior, en este caso si la URL incluye rel=”prev” estas no van a ser consideradas como duplicadas en los tabs Onpage como Title, Description, H1, H2. En algunos casos te vas a topar con que el contenido paginado te lo muestra como contenido duplicado, con esta opción lo evitas.
- Always follow redirects: Con esta opción habilitada le dices a la araña que siga las redirecciones hasta que llegue al final (solo en modo lista o List Mode) e ignora la opción anterior de la profundidad de rastreo.
- Always follow canonicals: funciona solo en List Mode e ignora la profundidad de rastreo y permite a la araña a continuar hasta el final las redirecciones en las URLs canonicals.
- Respect noindex: si esta chequeado, las URLs con el meta robots NOINDEX no se van tomar en cuenta. Si van a ser rastreadas y sus enlaces externos seguidos, pero no van a aparecer en los resultados del rastreo.
- Respect canonical: si esta chequeda, las URLs que estén canonizadas hacia otra URL, no van a ser tomadas en cuenta. Si van a ser rastreadas y sus enlaces externos seguidos, pero no van a aparecer en los resultados del rastreo.
- Respect next/prev: Si esta chequeada, solo va a ser reportada la primera URL con el rel=”next”. Si van a ser rastreadas y sus enlaces externos seguidos, pero no van a aparecer en los resultados del rastreo.
- Respect HSTS policy: Esto significa que si esta chequeado la araña va a hacer las peticiones únicamente por HTTPS inclusive si la URL rastreada este con HTTP. Cuando esto suceda, estas URLs van a estar marcadas con el código HTTP 307, que es “HSTS Policy”.
- Respect self referencing meta refresh: Si por alguna razon las URLs tienen configurado el Meta Refresh hacia si mismos, con esta opcion puedes decirle a la araña que lo ignore y evitar refrescos inncesarios.
- Extract images from img srcset attribute: Si se habilita va a extraer las imagnes del atributo SRCSET del tag <img>. Muy útil para validar cuando tenemos imágenes de distintos tamaños según el dispositivo y queremos validar que devueltan un estado 200.
- Crawl fragment identifiers: Si se habilita, la araña va a rastrear las URLs que tienen el hashtag en ella, como por ejemplo en las tablas de contenido o anchors. Default esto es ignorado, pero puedes usarlo para validar si las anclas o las tablas de contenido estan bien hechos.
- Response timeout: La araña espera 20 segundos para tomar URLs HTTP por default, con esta opción puedes incrementar dicho valor. Por lo general se hace en sitios realmente lentos. Es decir, la araña espera hasta 20 segundos para obtener la web, pasado este tiempo lo marca como error, pero si tu sabes que la web es muy lenta, puedes usar esta opción para que espere más tiempo.
- 5XX response retries: Si la araña recibe un error 5XX (el más común es el 503), como son errores temporales, puedes configurar para que intente X cantidad de veces antes de marcarlo como error.
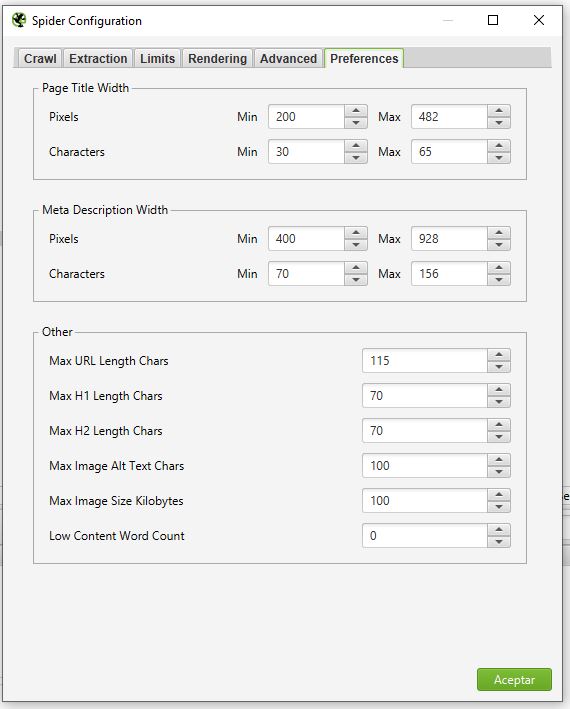
- Preferences: En esta sección configuras los parámetros para los metas title/description, longitud de URL etc. Estos parámetros configurados son los que se usaran para definir si estos datos están bien o mal en las webs escaneadas.
Por lo general no tendrás que editar algo de aquí.
- Content: Estas opciones sirven para configurar el comportamiento de la herramienta con respecto al contenido y consta de 3 apartados.
- Area: Esta es una configuración interesante cuando se quiere analizar el contenido, ya sea para contar el contenido, analizar la gramática o buscar contenido que pudiera ser duplicado.
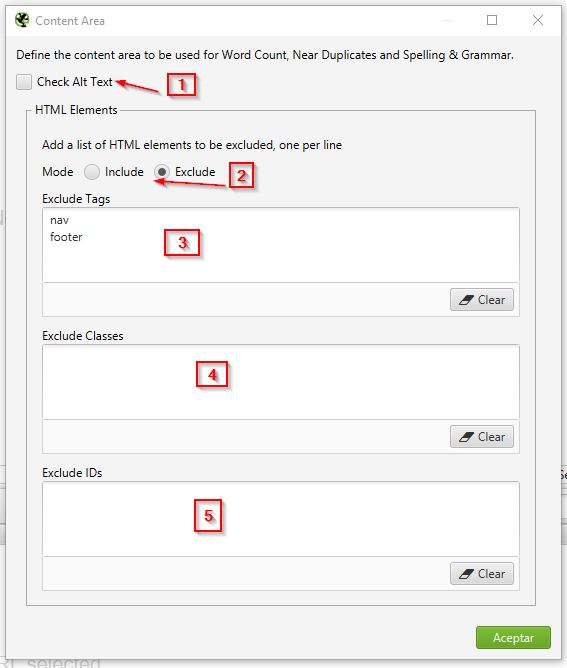
- Check Alt Text: Se le indica si la configuración seleccionada aplica para los ALT Texts de las imágenes.
- Mode: Le indicas si la lista de elementos HTML van a ser incluidos o excluidos. Por ejemplo, si tú sabes que tu web tiene todo el contenido en la etiqueta HTML <main> puedes usar “Include” y en Tags colocar <main>. Aquí lo importante es que identifiques en que tag está el contenido, o algún ID o CSS Class. También puedes hacerlo por exclusión, pero la verdad es más sencillo eligiendo el donde esta.
- Include/Exclude tags: aquí especificas los tags HTML donde esta o donde no está el contenido.
- Include/Exclude Classes: en este caso especificas clases de CSS que pueden o no contener el contenido.
- Include/Exclude IDs: aquí lo haces mediante los IDs de los tags.
Como nota personal, creo que sería mejor si el incluir/excluir fuera por sección y no global, ya que podrías incluir un tag, con ciertas clases y excluir algunos IDs. Espero que Screaming Frog lo haga.
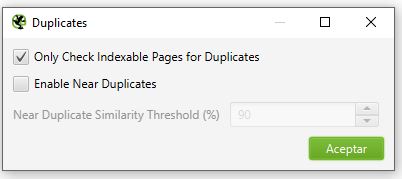
- Duplicates: En esta configuración le dices a Screaming Frog si el contenido duplicado lo considere solo en las páginas indexables y además puedes decirle que habilite el posible contenido duplicado (near duplicate content) y el % de parecido que debería tener una URL con otra para considerarse duplicado. Muy interesante para analizar nuestro propio contenido.
- Spelling & Grammar: En esta parte de la configuración, puedes habilitar si quieres que del contenido revise la ortografía y la gramática, una opción no muy depurada pero que te puede ayudar.
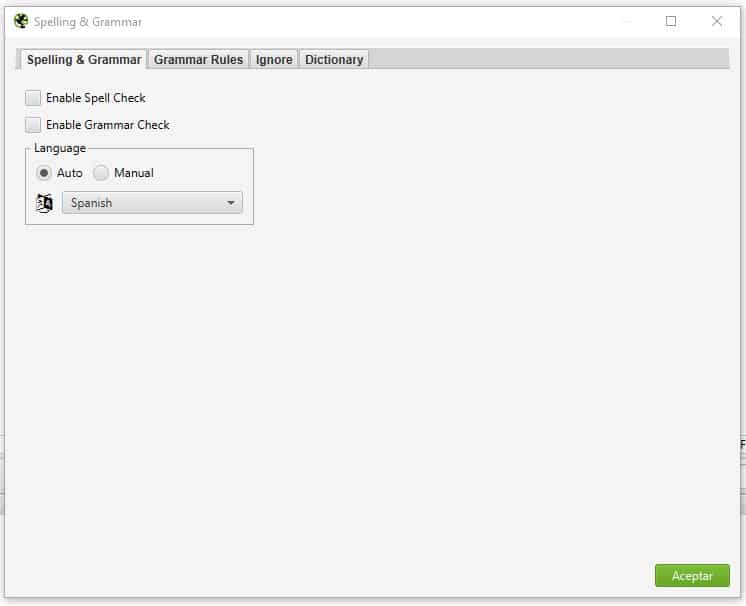
Consta de algunos tabs y opciones en cada uno.- Tab Spelling & Grammar: básicamente para habilitar la revisión y en qué idioma hacerlo.
- Enable Spell check: para decirle si habilita la revisión de ortografía.
- Enable Grammar Check: para decirle si habilita la revisión de la gramatica.
- Language: Para elegir el lenguaje de la página a analizar, consta de dos opciones: Auto, que usa el atributo de HTML lang para elegir en que idioma esta la web, y Manual, donde especificas manualmente el idioma y lo seleccionas del listado disponible.
Si vas a hacer uso de estas opciones, si deseas identificar si tu HTML está pasando correctamente el idioma, ponlo en automático, si sabes que si lo hace bien, para evitar problemas después de un largo crawl, mejor ponerlo en manual y elegir el idioma.
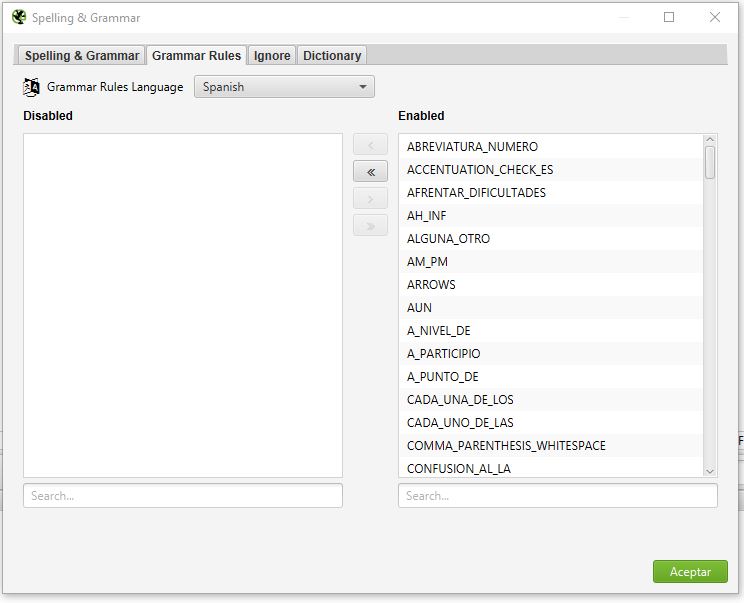
- Tab Grammar Rules: aquí le dices que reglas de gramática quieres que aplique, por lo general todas están habilitadas y a menos que sepas lo que haces, o si tienes una razón en particular, no deberías deshabilitar ninguna. Para habilitar/deshabilitar, solo debes pasar de un lado al otro las reglas.
- Tab Ignore: Aquí puedes agregar una lista de palabras o frases que deseas que el analizador ignore, se agregan una por línea. Cabe mencionar que lo configurado aquí solo funciona para el rastreo actual.
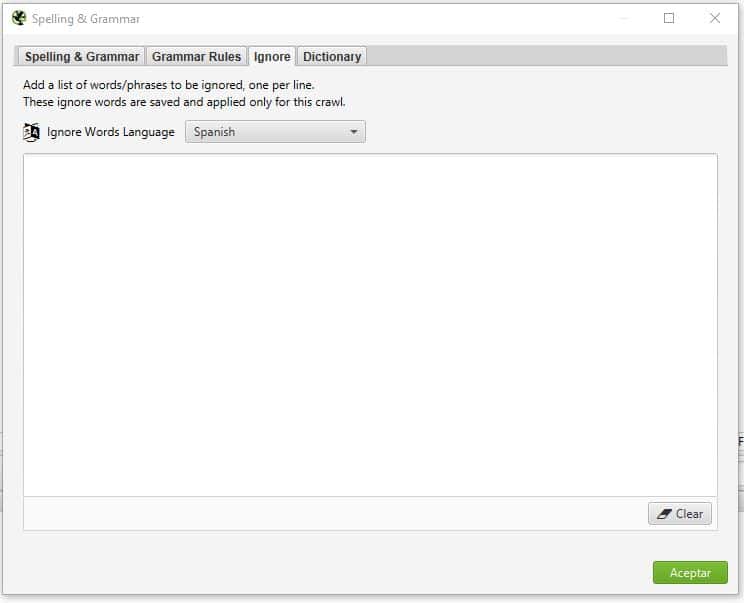
- Tab Dictionary: Esto es igual al tab anterior con la única diferencia que este listado va a aplicar para todos los rastreos que hagas. Es decir, no se limpia en cada web que pases.
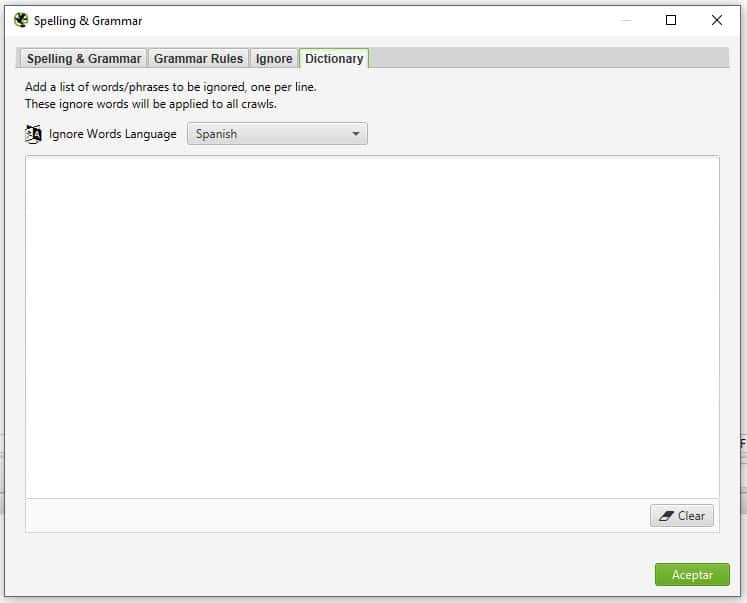
- Tab Spelling & Grammar: básicamente para habilitar la revisión y en qué idioma hacerlo.
- Robots txt: son las configuraciones de cómo debe interpretar el robots.txt el crawler. Consta de solo 2 opciones.
- Robots settings

- Selector: aqui eliges entre las opciones de respect robots.txt, que significa que va a respetar las reglas del archivo robots.txt, si tienes una regla de no permitir el user agent de screaming frog (Screaming Frog SEO Spider), pues no va a rastrear nada, ojo con esto. Ignore robots.txt, en este caso va a hacer caso omiso de las reglas en el robots.txt, asi que cualquier URL o bot bloqueado va a ser ignorado y por ende rastreado. Ignore robots.txt but report status: es igual al anterior pero nos indicara en los resultados si la URL rastreada estaba bloqueada o no por el robots.txt.
- Show internal URLs Blocked by robots.txt: con esto le decimos que en los resultados nos muestre si las URLs internas estan o no bloqueadas en el robots.txt, muy útil para identificar bloqueos de URLs por error.
- Show External URLs blocked by robots.txt: igual que lo anterior solo que con las URLs externas.
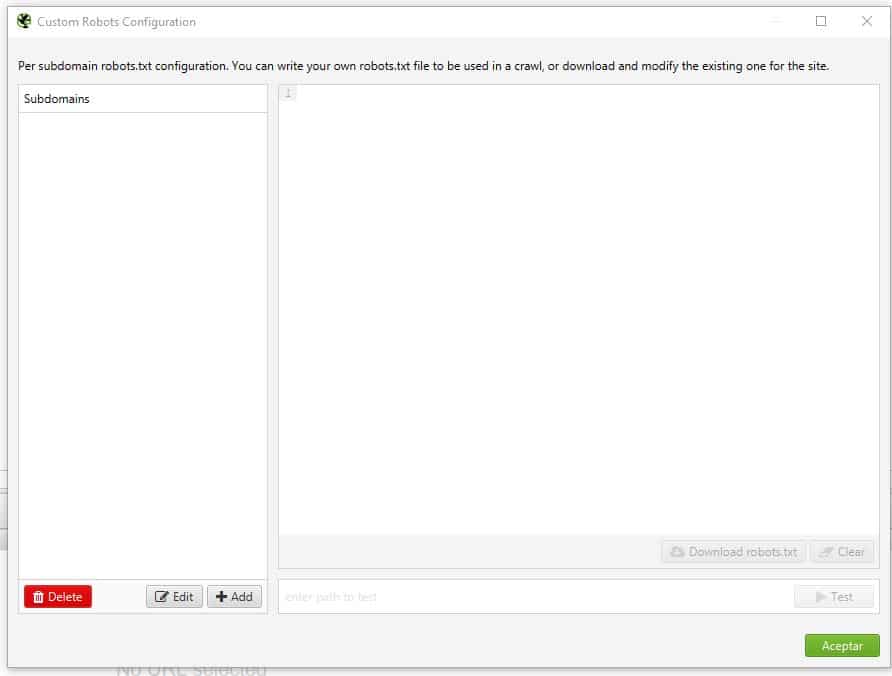
- Custom Robots Configuration: con esta opción puedes poner escribir un robots.txt experimental (ya sea bajando el que ya tienes y pegándolo o haciéndolo de cero), y con el rastreo veras como se comportaría el bot cuando pase por la web. Tiene la particularidad de poder configurase por subdominio, es decir, puedes poner un robots.txt para www, otro sin www, otro para testing., etc.
En configuración existen una decena más de opciones a configurar pero la mayoría de ellos no los vamos a necesitar por ahora y si me pusiera a explicar cada opción se volvería interminable, así que he decidido abordar las configuraciones a medida las vayamos necesitando.
- Robots settings
- Area: Esta es una configuración interesante cuando se quiere analizar el contenido, ya sea para contar el contenido, analizar la gramática o buscar contenido que pudiera ser duplicado.
- Crawl: Las opciones de que debe rastrear y almacenar la araña
- Spider: Las opciones de que y como debe rastrear la araña
-
- Mode: eliges el modo en que deseas ejecutar Screaming Frog, veamos cada uno de ellos:
- Spider: es el uso más común y consiste en que SF se comporte como un crawler, es decir, le das una URL y rastrea todas las URLs siguiendo los enlaces que encuentra.
Cuando está en modo SPIDER, la pantalla es como la siguiente:
- List: Con este modo, puedes proporcionarle una lista de URLs que tengas, por ejemplo, extraídas de otra herramienta o simplemente una lista de URLs de tu interés. En este caso, Screaming Frog extraerá la información únicamente de las URLs puestas en dicha lista. La interfaz cambia a la siguiente:Cabe mencionar que cuando se usa este modo, no se extrae más de las URLs, no imágenes, no enlaces externos, etc. También, en automático coloca el Limit Crawl Depth en 0 pero todo esto puede reconfigurarse para que si rastree otros elementos, pero lo hará únicamente con lo que este dentro de dicho espacio. No te preocupes si no queda claro en este momento, más adelante lo veremos con más calma.


- SERP: este modo es muy interesante. No rastrea nada, únicamente puedes subir una lista de meta titles and descriptions y Screaming Frog va a calcular su longitud y ancho en pixeles. ¿Uso práctico? Puedes rastrear tu web, editar en un excel los títulos y descripciones y luego subirlos para saber si están bien en largo de caracteres y pixeles, también podrás ver como se verán en los resultados de búsqueda, de nuevo, no te preocupes, más adelante lo probaremos.
La interfaz cambia a la siguiente:

- Spider: es el uso más común y consiste en que SF se comporte como un crawler, es decir, le das una URL y rastrea todas las URLs siguiendo los enlaces que encuentra.
- Bulk Export: Aquí encuentras muchas opciones para exportar los datos rastreados. Es muy amplio, aunque no complicado. Iremos viendo uno a uno más adelante. Nuevamente, si me detengo a explicar todos aquí mismo, se volvería poco práctica esta parte de la guía.
- Reports: Son un listado variado de reportes que puedes obtener desde la herramienta. Al igual que el caso anterior, a medida los vayamos necesitando/usando los iré explicando.
- Sitemap: permite crear un sitemap a partir de las URLs y/o imágenes rastreadas por el crawler.
- Visualisations: unos reportes muy interesantes que se explican mejor con ejemplos. Más adelante veremos su utilidad.
- Crawl Analysis: Son datos que se pueden calcular una vez se ha rastreado una web (completa o no). Veamos las opciones una a una:
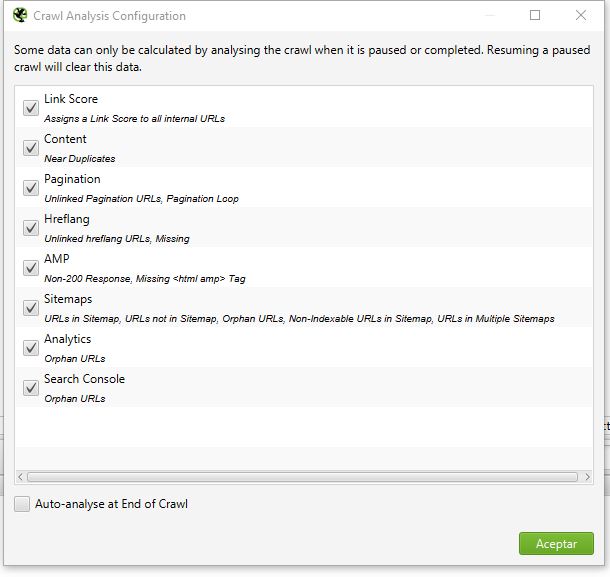
- Link Score: Esta es una puntuación que calcula Screaming Frog, algo asi como el page Rank interno de las URLs. Es solo una aproximación, pero la verdad es muy útil para ver como tenemos distribuidos nuestro enlazado interno.
- Content: si se ha configurado la opción de “Near Duplicates” en la configuración, activando esta opción realizara los cálculos necesarios para determinar que contenidos pueden ser considerados casi duplicados.
- Pagination: análisis de la paginación. Se puede ver si ha URLs con problemas en la paginación.
- Hreflang: si se está utilizando hreflang, con esta opción se analiza si está bien colocado, si hay URLs donde no este colocado, etc.
- AMP: chequea si la implemenacion de AMP esta funcionando, por ejemplo si hay URLs que no estan respondiendo con un código 200, o que no tengan implementada la etiqueta HTML AMP.
- Sitemaps: analiza el sitemap y obtiene que URLs estan presentes en él, cuáles no, URLs huérfanas, URLs no indexables en el sitemap, etc
- Analytics y Search Console: en la configuración se puede conectar el crawleo con Analytics y Search Console (entre otros) y con este análisis, Screaming Frog obtiene las URLs huérfanas a partir de la información que recoge Analytics y GSC.
- Auto-analyse at End of Crawl: por defecto, este análisis se ejecuta manualmente desde el menú, pero si se marca esta casilla al terminar el crawler, automáticamente realiza el análisis. Recomiendo no marcarlo a menos que estés seguro de que necesitas la información ya que dependiendo del tamaño de la web puedes sumar uso de RAM innecesariamente.
- License: para colocar tu licencia y poder quitar las limitaciones de la version Free.
- Help: La ayuda de la herramienta.
- Mode: eliges el modo en que deseas ejecutar Screaming Frog, veamos cada uno de ellos:
Y esto sería todo en lo que al menu respecta por el momento. He dejado muchas cosas por fuera pero no te preocupes, a medida vayamos usando la herramienta iré explicando otras opciones.
2- Barra de direcciones
La barra de direcciones o barra de URL, es el espacio donde puedes colocar la URL a rastrear.
3- Tabs principales
Son todas las opciones o filtros sobre la información rastreada. Cada tab tiene un filtro adicional con diferentes opciones según el tab y también se puede cambiar de vista (Lista y árbol):
Cada tab tiene su propio listado de columnas también, pero al ser tantos a medida los vayamos utilizando los iras entendiendo.
Tip: Puedes ordenar los tabs como prefieras arrastrando el tab a la posición deseada.
Veamos los principales:
- Internal: todas las URLs internas rastreadas, y se pueden filtrar por HTML, CSS, Javascript, Imágenes, PDF, etc
- External: todas las URLs externas rastreadas (si la opción está habilitada) y contiene los mismos filtros de las internas.
- Response codes: para filtrar las URLs según su código de respuesta: 2XX, 3XX, 4XX, 5XX, etc
- URL: en este caso se analizan las URLs y puedes filtrar por las que contienen caracteres no ASCII, las que tienen guion bajo, mayúsculas, barras multiples como por ejemplo //, etc
- Page Title: se analizan los meta titles de las URLs rastreadas y se puede filtrar por las que no tienen la etiqueta (missing), duplicadas, las que son muy largas, muy cortas, por ancho en pixeles, multiple (si la etiqueta esta puesta más de una vez), etc
- Meta Description: lo mismo que con meta title, solo que analizando las descripciones.
- Meta Keywords: igual que los anteriores, solo que analizando la etiqueta (que prácticamente ya no se usa) de meta keywords.
- H1 y H2: estos dos tabs analizan si los headings H1 y H2 de las URLs rastreadas y se pueden filtrar por las URLs que no los tienen, si hay duplicados, muy largos, multiple, etc.
- Content: Muestra la inforamcion relacionada al contenido de las URLs internas rastraedas, lo que incluye detalles de la cantidad de palabras, contenido duplicado, casi duplicado, errores de gramática, etc, para que te funcione bien, debes configurar el área del contenido en “Configuration > Content > Area” y defenir según la web, donde se encuentra el contenido. Puedes ver esta explicación más arriba.
- Canonicals: para ver las URLs rastreadas vs su canonical (rel=”canonical”), sus filtros son:
- Contains Canonical: filtra las URLs que tienen presente la etiqueta.
- Self Referencing: filtra las URLs que tienen la etiqueta y que dicha etiqueta hace referencia a si misma, por ejemplo https://miweb.com tiene <link rel=»canonical» href=»https://miweb.com» >
- Canonicalised: al contrario de la opción anterior, esta muestra todas las URLs con la etiqueta canonical presente pero que apunta a otra URL, por ejemplo la URL https://miweb.com tiene <link rel=»canonical» href=»https://www.miweb.com/» >
- Missing: filtra las URLs que no tienen presente la etiqueta canonical.
- Multiple: para filtrar las URLs que tengan más de una vez la etiqueta.
- Non-Indexable Canonical: filtra aquellas URLs que contiene la etiqueta canonical pero que esta apunta a una URL que no es indexable.
- Images: para analizar la imágenes rastreadas en la web. Puedes filtrar por aquellas que pesen más de 100kb, las que tengan el atributo ALT TEXT vacio, las que no tengan el atributo ALT TEXT, y las que tengan el ALT Text demasiado largo.
- Pagination: analiza la inforamacion de rel=”next” y rel=”prev” que se hayan encontrado en el rastreo, es decir, las paginaciones. Los filtros disponibles son:
- Contains Pagination: lista todas las URLs que tienen paginación con rel prev y next.
- First Page: lista las URLs que solo tienen rel=”next”, es decir, donde empieza una paginación.
- Paginated 2+ Pages: lista las URLs que solo tienen el rel=”prev”, indicando que no es la primera página de la paginación.
- Pagination URL Not In Anchor Tag: para identificar paginaciones que no están contenidas con la etiqueta <a> (anchor tag), es decir, no son enlaces que el robot de Google pueda seguir y traspasar autoridad.
- Non-200 Pagination URL: contiene paginación con NEXT, PREV, pero la URL a la que apuntan no responde con un código de estado 200.
- Unlinked Pagination URL: requiere realizar el “crawl analysis” para ser calculado. Aquí filtras las URLs que tienen rel=”next” o “prev” que no están vinculadas en el sitio.
- Non-Indexable: para ver las URLs paginadas que no son indexables. La forma más común de que esto suceda es cuando de la página 2 en adelante se canonizan a la pagina 1.
- Multiple Pagination URLs: cuando los atributos rel=”next” y “prev” están presentes más de una vez en la URL.
- Pagination Loop: al igual que Unlinked Pagination URL, se requiere del crawl analysis para ser calculado y muestra las URLs que con el contenido de sus atributos NEXT y PREV hacen referencia a ellas mismas, por ejemplo la pagina 2 tiene un rel=”next” o prev hacia la misma página 2.
- Sequence error: muestra las URLs que tienen errores en la secuencia de sus URLs Next y Prev perdiendo la relación de la serie paginada.
- Directives: muestra la información de la etiqueta META ROBOTS, y X-Robots-Tag en el HTTP Header, por ejemplo NOINDEX, FOLLOW, etc. Y los filtros disponibles se basan en los posibles valores de estas etiquetas.
- Hreflang: analiza el contenido de esta etiqueta si está presente. Sus filtros son:
- Contains Hreflang: filtra las URLs que contienen la etiqueta.
- Non-200 Hreflang URLs: filtra las URLs que tienen rel=”alternate” que apuntan a una URL que no devuelve un código HTTP 200, como por ejemplo URLs bloqueadas por robots, errores 404, redirecciones etc.
- Unlinked Hreflang URLs: muestra las URLs que solo pueden ser descubiertas por el Hreflang, es decir, una URL que no tiene enlaces más que el Hreflang.
- Missing Return Links: Muestra las URLs que no tienen un enlace de retorno. Hreflang es reciproco, es decir, lo que está en la web A debe apuntar a la B y viceversa, con este filtro vemos aquellas que no son reciprocas.
- Inconsistent Language & Region Return Links: Filtra las URLs que tienen inconsistencias en el valor de lenguaje, por ejemplo que la URL A diga que la B es Francés y en la B diga que ella es Alemán. Todos los problemas de este tipo se pueden ver con este filtro.
- Non Canonical Return links: se pueden ver las URLs que con Hreflang apuntan a URLs que no son canonicals, por ejemplo, la web A dice con Hreflang que su equivalente en la web B es http://ingles.miweb.com y la URL canonical de dicha URL es https://ingles.miweb.com/
- Noindex Return Links: para ver las URLs que apuntan a paginas NOINDEX.
- Incorrect Language & Region Codes: para ver las URLs que tienen códigos de lenguaje equivocados.
- Multiple Entries: En este caso se ven las URLs que indican varias URLs para el mismo idioma, por ejemplo, la web A en español indica que la B y C son en inglés con el mismo código “en”.
- Missing Self Reference: muestra las URLs que no tienen la referencia a si mismas, ya que Hreflang debe referenciar las URLs a sí mismas también.
- Not Using Canonical: muestra las URLs que no usan canonical pero que tienen Hreflang. Hreflang debe estar presente únicamente en URLs con canonical.
- Missing X-Default: muestra las URLs que no tienen el atributo X-Default, al ser opcional no significa que sean URLs con problemas.
- Missing: Muestra las URLs que no tienen presente Ahreflang. Recuerda que esto es válido si la web no tiene versiones en otros idiomas.
- AJAX: este tab hace referencia a una forma que Google tenia para rastrear páginas con AJAX que ahora ya está obsoleto.
Si el sitio está hecho con Javascript del lado del cliente, es decir, que el sitio se construye del lado del cliente (y no del servidor) aquí puedes ver algunas opciones. Está disponible únicamente en la versión de pago de Screaming Frog y lo que hace es renderizar la web hecha en JS como si fuera un navegador moderno. - AMP: sirve para ver las URLs con AMP descubiertas durante el rastreo. Puedes filtrar acorde a los posibles problemas que puedas encontrar con AMP.
- Structured Data: incluye la información y problemas de validación descubiertas durante el rastreo, en schema puesto con JSON-LD, Microdata, RDFa, etc. Para que esta información sea recopilada debe ser configurada en Configuration->spider->Extraction. Se puede filtrar por aquellas URLs que tienen datos estructurados, las que no, las que tienen errores de validación, las que tienen advertencias, etc
- Sitemaps: Para ver las URLs que han sido rastreadas y que se pueden filtrar según la información presente en el sitemap. Se puede filtrar por las URLs que estan en el Sitemap, las que no, las URLs huérfanas, que son aquellas presentes en el Sitemap pero no en el rastreo, esto puede suceder porque están en el sitemap por error o no están enlazadas internamente de ninguna forma rastreable, URLs no indexables en el sitemap, etc
- Pagespeed: Muestra la información obtenida desde Pagespeed Insights el cual usa Lighthouse “lab data” y es posible ver los datos “real-wordl” desde Chrome User Experience Report (CrUX o “field data). Para poder obtener esta información debe configurarse desde “Configuration > API Access > PageSpeed Insights” usando una clave gratis de la API de PageSpeed. Esta opción es muy buena para poder auditar la velocidad y experiencia de usuario de todas las URLs rastreadas.
Se puede filtrar por una gran cantidad de opciones, todas relacionadas a la velocidad de carga y experiencia de usuario. Si sabes de WPO esta herramienta te va a ser bastante útil. - Custom Search: Esta opción funciona si tienes configurado “Custom Search” en “Config > Custom > Search”. En este tab ves el resultado de dichas búsquedas configuradas. La aprenderás a usar más adelante.
- Custom Extraction: Al igual que la opción anterior, se muestra el resultado de lo que hayas configurado en “Config > Custom > Extraction” y lo veremos más adelante con detalle.
- Analytics: Si estas usando la API de Google Analytics que se puede configurar en “Configuration > API Access > Google Analytics” en este tab puedes ver la información obtenida desde GA. Puedes filtrar esta información por aquellas URLs que tienen 1 sesión o más, por alto bounce rate, las que no tienen información en GA, es decir, que no tienen sesiones; URLs que no son indexables con datos en GA y URLs huérfanas, es decir, que estan en GA pero que no están en el rastreo.
- Search Console: es lo mismo que con GA pero con datos extraidos desde GSC.
- Link Metrics: si has configurado las APIs de Majescti, Ahrefs y/o MOZ, en este tab podrás ver la información extraída para dichas URLs rastreadas.
- Security: Muestra la información relacionada a la seguridad de las URLs internas. Se puede filtrar por URLs con HTTP, las que son con HTTPS, con contenido mixto, URLs con formularios que estan sobre HTTP, etc.
4- Botones
Estos son los botones para iniciar el rastreo o limpiar el rastreo hecho.
5- Barra de rastreo y análisis
Aquí podrás ver el % de rastreo y análisis que lleva la web analizada. Si tienes una web con miles de URLs el proceso puede ser lento y aquí puedes ver cómo va avanzando.
6- Buscar (Filtrar por búsqueda)
Con este buscador puedes filtrar cualquier cosa que este en los datos rastreados y con el selector puedes elegir sobre qué elementos hacer la búsqueda, como la URL, un código de estado HTTP, etc.
7- Panel derecho / Tabs
En estos paneles puedes ver diferentes resúmenes de lo que se ha rastreado. Veamos cada uno de ellos.
8- Overview
Se actualiza en tiempo real y provee la información más relevante de lo que se está rastreando, así como un resumen del total de la información de las URLs en cada tab principal. Contiene 2 apartados:
- Summary: Un resumen de las URLs que se han encontrado.
- Crawl Data: Un resumen del total de URLs y estados de cada tab principal y sus filtros.
9- Data rastreada
En este panel se presenta toda la información rastreada y cambia a medida cambias de tab (en los tabs principales).
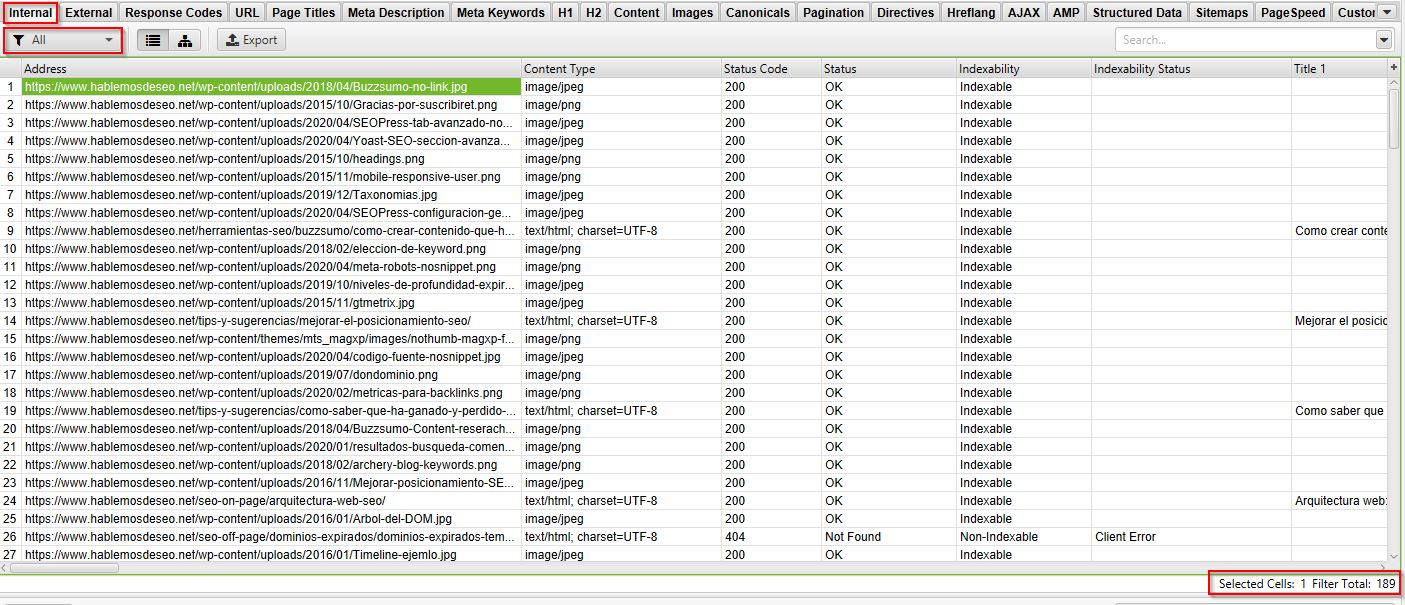
10- Contador
En esta parte puedes ver el total de filas en el tab actual y además si has seleccionado algunas te las contabiliza.
Por ejemplo, en este caso el total lo rastreado son 189 filas:
Pero si cambio el filtro a solo HTML, el total cambia:
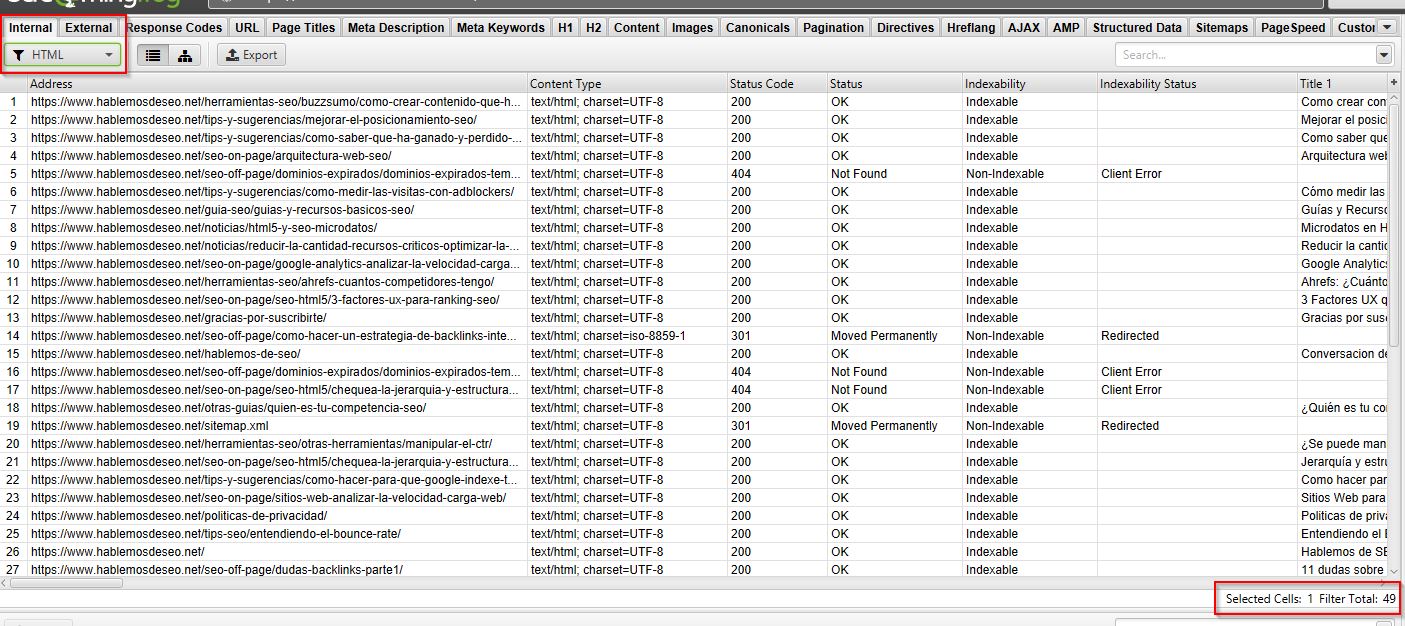
Al igual, si realizas un filtro por búsqueda, también cambia el total:
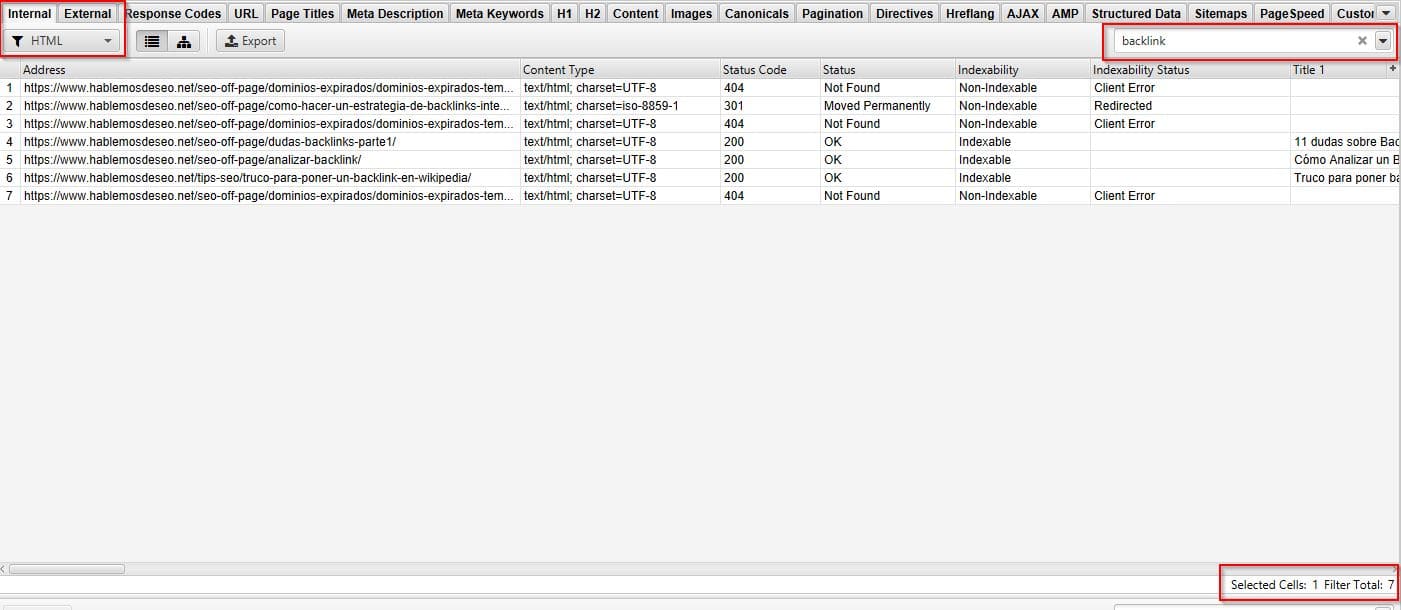
11- Búsqueda en tabs inferiores
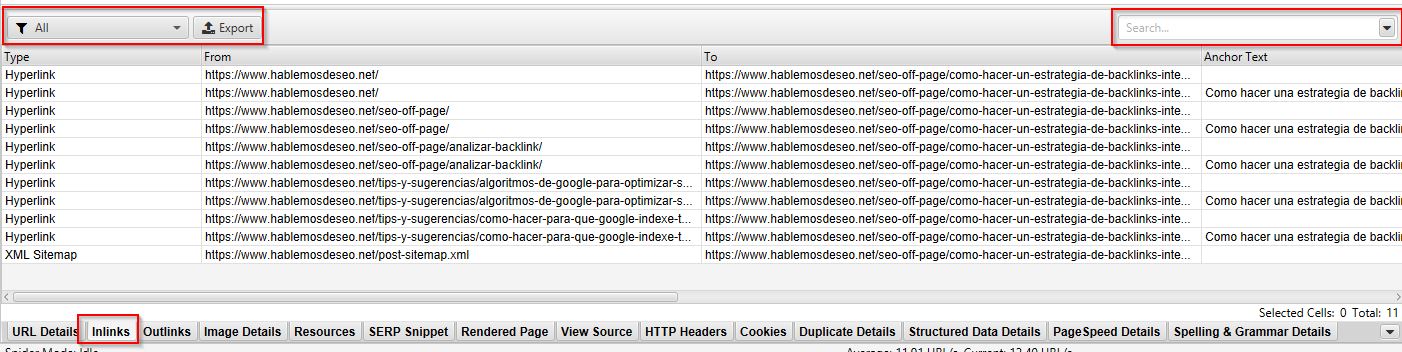
Este buscador funciona similar al de los paneles superiores (6) con la única diferencia de que funciona o filtra en los tabs inferiores.
Por ejemplo, en este caso estoy viendo los Inlinks de una URL seleccionada:
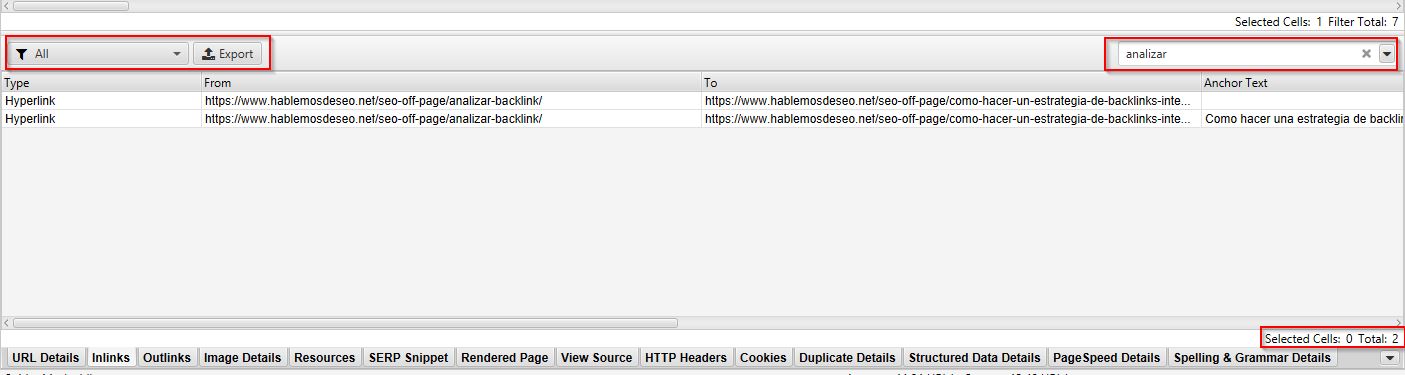
Si busco algo en la caja de búsqueda los resultados se filtran:
12- Información de los tabs (paneles) inferiores
En esta sección veras los datos correspondientes a los tabs o paneles inferiores, que al momento de escribir este artículo eran 14.
Nota: este panel muestra información únicamente cuando has seleccionado una fila de la data rastreada (9), si seleccionas más de uno, no muestra información.
13- Paneles inferiores
Veamos que encuentras en cada uno:
- URL Details: La información detallada de la URL seleccionada.
- Inlinks: todos los enlaces internos que apuntan a la URL seleccionada.
- Outlinks: todos los enlaces salientes que se encuentra en la URL seleccionada. Ojo, no externos, sino los enlaces que desde dicha URL van a otro lugar.
- Image Details: Muestra la lista de imágenes en dicha URL, puedes hacer el preview y ver el ALT Text que tienen.
- Resources: un listado de recursos utilizados en la URL como JS o imágenes o CSS.
- SERP Snippet: nos da un preview de cómo se vería el snippet en los resultados de búsqueda (SERP) y nos permite cambiar entre diferentes dispositivos (escritorio, móvil) así como también modificar la descripción para tener una idea de cómo se vería antes de realizar el cambio real en la web. Muy útil.
- Rendered Page: aquí puedes visualizar como se renderiza la URL pero solo puede verse si se ha habilitado el renderizado por JavaScript en la configuración.
- View Source: Muestra HTML fuente y el renderizado de la URL y el, para que lo muestre, en la configuración debe estar habilitado almacenar el HTML en “Configuration > Spider > Extraction > Store HTML / Store Rendered HTML. Tambien va a requerir que se configure para renderizar por Javascript en “Configuration > Spider > Rendering”.
En el panel de la izquierda ves el código fuente original y a la derecha el renderizado, algo interesante es que seleccionando el checkbox “Show differences” puedes ver diferencias entre ambos:
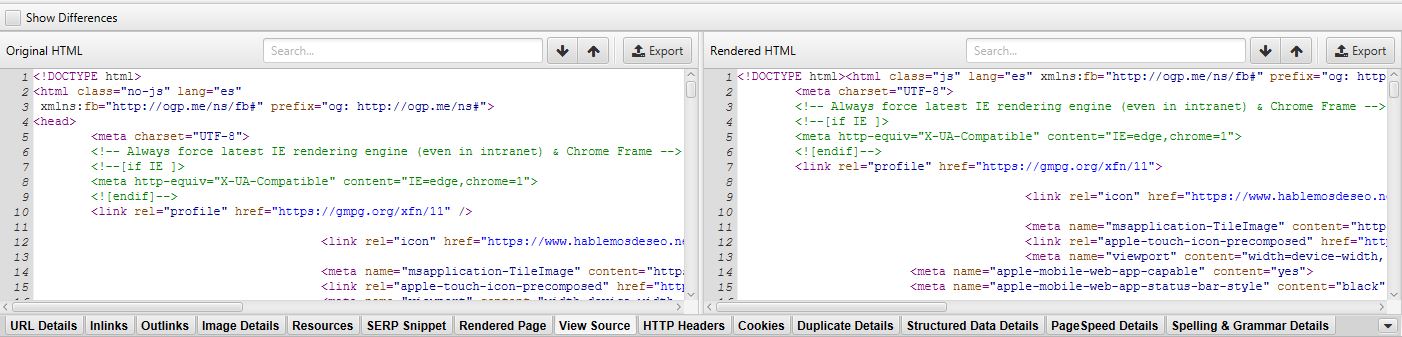
- HTTP Headers: Aquí puedes ver los headers completos HTTP, tanto de solicitud como de respuesta, debes tenerlos activos en “Configuration > Spider > Extraction > HTTP Headers”.
En el panel de la izquierda ves la petición, en la derecha la respuesta:
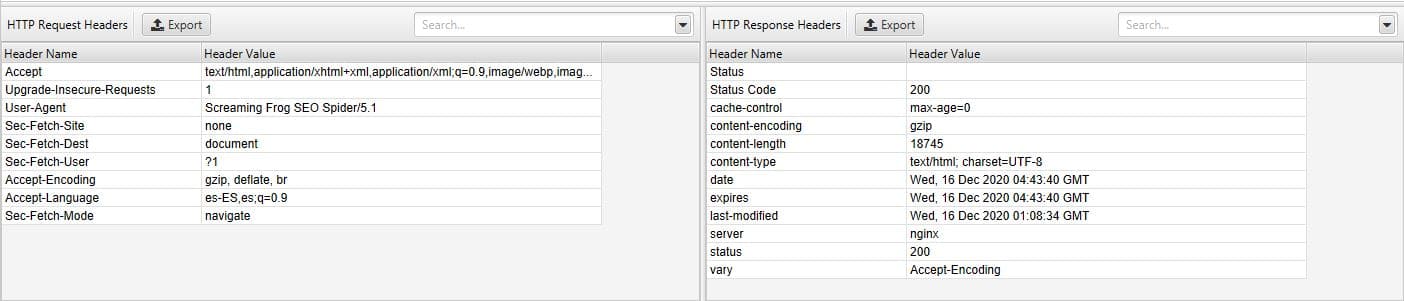
- Cookies: puedes ver las cookies encontradas durante el rastreo, para que puedas verlos debes tener activada la opción en ‘Configuration > Spider > Extraction > Cookies’ y debes tener habilitado el render por JavaScript en “Configuration > Spider > Rendering”.
- Duplicate Details: Muestra el detalle de cualquier duplicado exacto o cerca de ser duplicado. Para esto debe estar habilitada la opción de duplicados en “Configuration > Content > Duplicates” y luego de rastrear debe llevarse a cabo el Crawl Analysis.
- Structured Data Details: puedes ver la información de los datos estructurados de la URL seleccionada. Para que muestre la info debes configurarlo en ‘Configuration > Spider > Extraction > JSON-LD/Microdata/RDFa & Schema.org Validation/Google Validation’.
En el panel izquierdo se puede ver la información de los datos estructurados y en el de la derecha la validación con sus advertencias y/o errores si los tuviera.
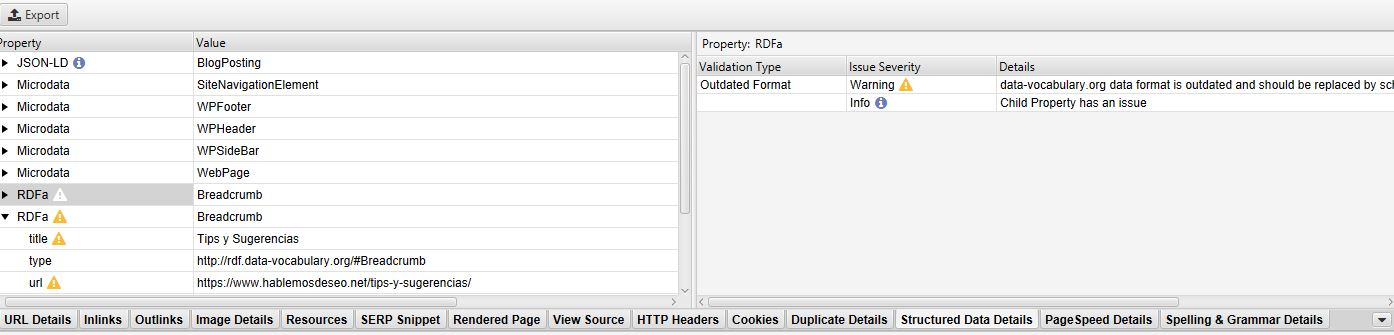
- Page Speed Details: Cuando has integrado la API de Page Speed Insights puedes ver los datos obtenidos para la URL seleccionada.
- Spelling & Grammar Details: Si has configurado para que analice la ortografía y gramática, en este panel puedes ver los detalles de los errores que se han encontrado.
14- Gráfico de crawleo de los tabs principales
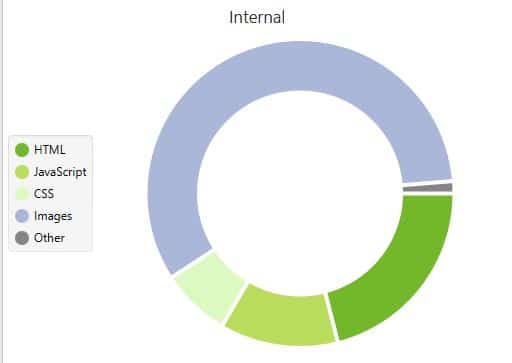
Según el panel superior elegido, te muestra un gráfico de anillo con la distribución de los datos recopilados según el tipo de dato. En palabras más sencillas, el grafico se compone de cuantas URLs hay en el tab seleccionado por filtro disponible en dicho tab.
Ejemplo 1 – Internal
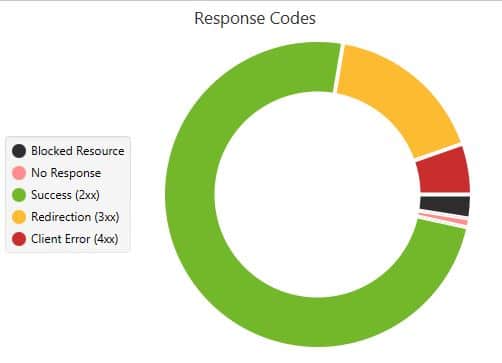
Ejemplo 2 – Response Codes
15- Modo seleccionado
Te muestra el modo en que Screaming Frog está funcionando: Spider, List o SERP.
Conclusión: ¿Qué aprendiste hoy?
Si hice algo bien, después de leer este articulo ya podrás instalar Screaming Frog y conocerás su interfaz, menú de navegación y opciones. De esta forma en las próximas guías cuando se mencione alguna opción que no se te haga familiar puedes recurrir a esta guía, te recomiendo guardarla en tus marcadores para que sea más fácil de encontrar.
Bueno, creo que es todo lo más relevante de la interfaz de Screaming Frog. Sé que en algunos puntos profundice más que otros pero quiero que me entiendas, si me ponía a hacer ejemplos de cada parte esta descripción se volvería interminable, y le puse más énfasis a detallar aquellos más simples y que al conocer que hace puedas comenzar a usar la herramienta sin esperar más guías de mi parte.
Si me hizo falta agregar alguna opción importante, házmelo saber en los comentarios, también agradecería cualquier crítica constructiva, aporte o simplemente tu opinión.
Si te ha gustado, no olvides compartir y dejar un comentario.
Nos vemos en el siguiente artículo: Primer rastreo y primer paso de la auditoría con Screaming Frog.





